
POI替换docx文件中的文本段的关键字
需求描述
需要在替换文本段中的关键字的同时还是需要保留该关键字的格式
例如:

期望的结果:

问题点
文本段在POI中是使用XWPFParagraph 存储的,而XWPFParagraph 又是通过保存了一个XWPFRun的列表来存储每个子文本段的,同时XWPFRun 也负责每个子文本段的格式。一段XWPFParagraph被拆分为多少个XWPFRun,这个由Word编辑器自己决定,因此可能就会存在关键字部分被拆分到多个XWPFRun中,因此如果直接通过获取XWPFParagraph 的整体的文本,再替换关键字,会导致丢失掉了关键字部分的格式。
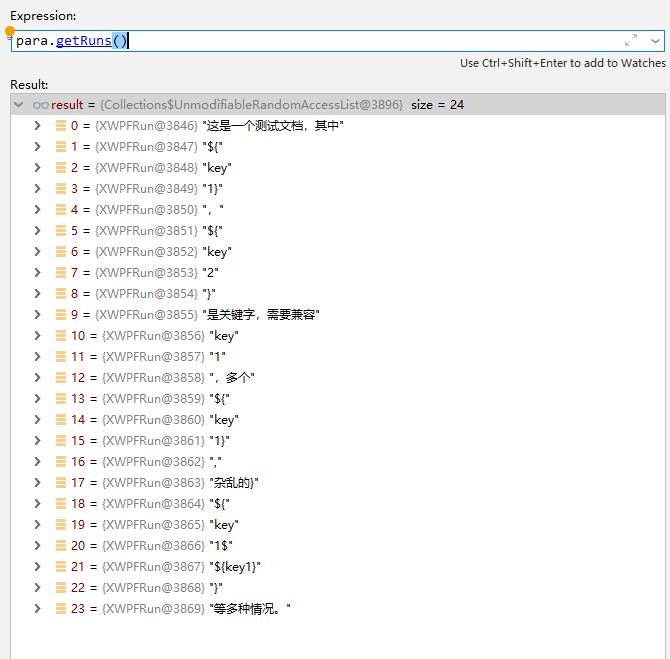
例如,上图中的内容在程序中XWPFParagraph中XWPFRun列表为:
实现
因此需要自己编写一个多个子字符串组成的字符串列表的关键字搜索算法,并能返回关键字所在的列表的下标。代码如下:
查找算法:
private static void replaceInParagraph(XWPFParagraph para, Map<String, Object> parameterMap) {
String paraText = para.getParagraphText();
if(!paraText.contains("${") || !paraText.contains("}") ){
return ;
}
log.info("paraText:【{}】",paraText);
List<XWPFRun> xwpfRuns = para.getRuns();
StringBuilder keySb = new StringBuilder();
boolean hasKey = false;
LinkedHashMap<String,XmlObject> newParaMap = new LinkedHashMap<>();
for(int i=0;i<xwpfRuns.size();i++){
XWPFRun run = xwpfRuns.get(i);
String str = run.text();
int bIndex =0;
int eIndex =0;
do{
int end = str.indexOf("}",eIndex);
//已经有关键字内容
if(hasKey){
if(end>=0) { //末尾
keySb.append(str.substring(bIndex,end));
eIndex = end + 1;
bIndex = eIndex;
String value = String.valueOf(parameterMap.getOrDefault(keySb.toString(),""));
//替换关键字内容
newParaMap.put(value,run.getCTR().copy());
keySb.setLength(0);
hasKey = false;
continue;
}else{
//有内容,但没有结束符,当前部分字符串作为关键字内容
keySb.append(str.substring(bIndex));
bIndex = str.length();
eIndex = bIndex;
}
}else{
//没有关键字内容
int begin = str.indexOf("$",eIndex);
if(end>=0 && end<begin){
//修正无效的结束符
newParaMap.put(str.substring(bIndex,end+1),run.getCTR().copy());
eIndex = end + 1;
bIndex = eIndex;
continue;
}
//存在起始符
if(begin>=0){
int begin1 = str.indexOf("${",begin);
//存在关键字内容起始符
if(begin1>=0){
//保存关键字起始符
hasKey = true;
bIndex = begin1+2;
eIndex = bIndex ;
continue;
}else{
//不存在关键字内容起始符,
//$ 是当前字符串末尾且不是数组最后一个元素
if(begin==str.length()-1 && i+1<xwpfRuns.size()){
int begin2 = xwpfRuns.get(i+1).text().indexOf("{");
// { 必须是下一个字符串元素的首字母
if(begin2==0){
hasKey = true;
i++;
run = xwpfRuns.get(i);
str = run.text();
bIndex=1;
eIndex=1;
continue;
}else{
//下一个数组元素的第一个字符不是{
newParaMap.put(str.substring(bIndex),run.getCTR().copy());
break;
}
}else{
//不是最后一个字符或者是最后一个元素
newParaMap.put(str.substring(bIndex),run.getCTR().copy());
break;
}
}
}else{
//不存在起始符
newParaMap.put(str.substring(bIndex),run.getCTR().copy());
break;
}
}
}while(bIndex<str.length());
}
replaceParagraph(para,newParaMap);
log.info("replaced paraText:【{}】",para.getParagraphText());
}
替换算法:
private static void replaceParagraph(XWPFParagraph para,LinkedHashMap<String,XmlObject> newParaMap){
if(CollectionUtils.isNotEmpty(para.getRuns())) {
//删除所有文本段
while(para.removeRun(0)) {
}
}
newParaMap.forEach((k,v)->{
//创建新文本段,并恢复格式
XWPFRun run = para.createRun();
run.getCTR().set(v);
run.setText(k,0);
});
}
总结
一开始想使用编译原理中的源码解析的方法处理,但后来发现这里token的关键字部分也可能被拆分,因此自己写了一个新的算法。
目前存在的问题是对于${key1$${key1}} 这种嵌套的关键字处理有争议,目前识别为key1$${key1},实际可能要识别成``${key1$ + key1 +}`